How does large companies like Google, Microsoft, or Amazon report count statistics accurately and in real time, fast? Easy, they cache these values.
More often than not, count values such as the infamous COUNT(*) in the SQL query "SELECT COUNT(*) FROM someTable;" are retrieved more often than updated. For example, counting the number of registered users, products, or posts in a thread.
It's absolutely valid to use COUNT(*) even on large datasets, since most database management systems are designed for such scenarios and are often very quick in their responses. However, there are often times when these quick responses slow down or are not reliably quick enough. Some scenarios include, real-time production sites with massive datasets (100 million records and up), datasets that require many joins before a count is possible, or a requirement of less than 0.01 seconds response over a 0.1 seconds response.
Many of these scenarios are align with real world problems, perhaps even faced by the reader. So why does a well designed and programmed database system choke on some of these requests? The answer: the values were not cached.
I'll compare this idea with the popular database system MYSQL. In MYSQL, there are two main types of engines, MYISAM and INNODB. Both types of database table engines are valid and good for their designed purposes. MYISAM is designed for fast inserts, updates, and selects, but can suffer from lock contention since the entire table needs to be locked before update operations can be performed. Note: Update operations include insert queries as well. Furthermore, MYISAM supports fulltext searches, which INNODB cannot.
On the other hand, INNODB is designed for more reliable use cases. INNODB uses row locking and transactions for update operations, none which is supported in MYISAM. This was a brief but suitable introduction to the two types of engines, as I will not go into debate over which is better.

MySQL Engines. MyISAM and InnoDB.
MYISAM caches COUNT queries, for example, in its metadata, it stores the number of records (rows) in the table. There are also other statistical cached metadata that it uses for joins. For example, selecting COUNT(*) in a cross joins is a simple multiplication of the totals in the tables if a restrictive clause is not used (WHERE clause). INNODB tables do not cache such values; although, there are methods that a database administrator can enable, but MYSQL specification states that results can be off by 50%. This is particular bad for important queries (bank statements).
What INNODB does is it finds the first record that matches the count requirement, and then iterates (using a cursor most likely) until it finds the end of all results it needs to count. This process could take a long time depending on the number of records in the table and number of records that match the requirement. An index only plan could help, but probably doesn't satisfy a sub hundredth requirement on massive datasets (100+ millions).
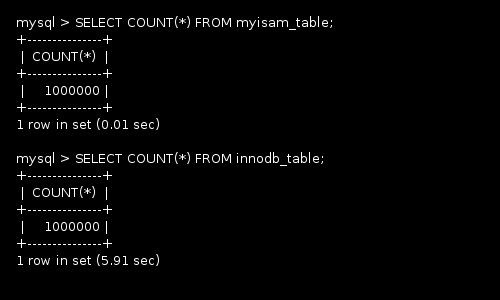
MyISAM and InnoDB COUNT(*) Speed. Counting in the InnoDB table is much slower.
Now that we understand the difference in engines and why some count queries are faster than other, we can discuss some strategies to overcome this problem. The strategies are to cache, cache, and cache some more.
So why do we cache? Caching allows the database to retrieve a single record (or a set) nearly instantly without having to do those expensive counts everytime a user requests a count query. On a real time production server such as e-commerce website, this could mean the difference of a happy and a fustrated customer.
There are inherent problems to caching, since the more you cache, the more space you will require to cache. For most users, space is not a problem since we are introduced to terabyte hard drives. A bigger concern is the time required to perform a cache. While this is a problem, a database administrator should map out the ratio of reads to updates to determine if caching is more beneficial. These problems are rooted to the basic problem similarly to "How many, and which indexes should we create?", but this is for another day and another article.
Finally, there are cases where caching is not possible. I'll mention a few, since I, at the moment, am not aware of how to speed up these counts. Perhaps someone can enlighten me. For example, how would you perform a quick count query on dynamic records where caching is not possible. One such scenario might be the number of records within a given timeframe where the timeframe is user specified (cannot be predetermined) and update operations are not necessarily mono-increasing. This is the abstracted problem from the common problem in a forum website where the webmaster wants to display the number of posts between a certain dates, quickly.
osSlvO I appreciate you sharing this blog.Thanks Again. Fantastic.
Very informative blog article.Really thank you! Will read on...
I really like and appreciate your post.Thanks Again. Will read on...
Im thankful for the blog article.Thanks Again. Fantastic.
I really like and appreciate your blog article.